# Import jupysql Jupyter extension to create SQL cells
%load_ext sql
%config SqlMagic.displaycon = False # hides con info
%config SqlMagic.autopandas = True # output as df
#%config SqlMagic.feedback = False #
%sql duckdb://SQL 101 with duckdb and jupysql
This notebook sql and matplotlibs its way to:
Jupyter + duckdb setup for sql
Before the sql even starts, I want to use jupyter notebooks + sql. I’m using duckdb inside jupyter to look at a few sql datasets.
First up, make a new env and install the necessary libraries if necessary by:
mamba create -n sql101 python=3.11 jupyterlab duckdb duckdb-engine jupysql matplotlib openpyxl plotly
mamba active sql101Setting up duckdb for jupyter
Once all the packages have been installed, setup jupyter to use duckdb. You don’t need to use all the three config options below, just noting some useful ones for future reference.
the %config SqlMagic.autopandas in particular is useful - the sql query is returned as a pandas dataframe. This is useful as even though right now I have a small dataset, on a real project duckdb can talk to remote databases, or query parquet files on the web, do a query and only pull down the subset of data selected in the query.
After that, the pandas dataframe is ideal for plotting and other pythonic stuff.
Data - Big Mac index
I’m using the Economist’s big mac gdp source data. Pandas can directly download the csv file into a dataframe which duckdb can read, but trying to stick with most sql here, so I’m downloading the csv file to disk and reading it with duckdb directly.
Why the big mac index? To calculate the big mac index we need to use correlated subqueries, which is a pretty advanced topic!
The final output figure Figure 1 is somewhere below, this notebook works through getting there slowly:
url = "https://github.com/TheEconomist/big-mac-data/raw/master/source-data/big-mac-source-data-v2.csv"
url = "https://github.com/TheEconomist/big-mac-data/raw/january-2023-update/source-data/big-mac-source-data-v2.csv"
fname = "big-mac-source-data-v2.csv"
with open(fname, "wb") as file:
file.write(requests.get(url).content)When using %%sql cells in jupyter, put python variables in brackets like so: {{var_name}}.
The read_csv_auto should auto-magically read and convert the csv to a sql table:
%%sql
-- make a table bigmac from the csv file
create table if not exists bigmac as select * from read_csv_auto('{{fname}}');
select * from bigmac limit 3; -- comments can go here too!| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | ARS | 2.50 | 1.00 | 8709.072 | 8709.072 | 2000-04-01 | 2.500000 | 0.116071 | 7803.328512 |
| 1 | Australia | AUS | AUD | 2.59 | 1.68 | 21746.809 | 33698.764 | 2000-04-01 | 1.541667 | -0.311756 | 29144.876973 |
| 2 | Brazil | BRA | BRL | 2.95 | 1.79 | 3501.438 | 6351.375 | 2000-04-01 | 1.648045 | -0.264266 | 4822.738983 |
So now we have a table inside a sql database.
Note
sql convention is to use a lot of CAPITALS, but for fast typing and a lack of an sql formatter, I’m going lowercase. Ideally your sql writing thingamjig should have a formatter which does that for you.
EDA and data cleanup
Data always has some issues, so taking a look:
Metadata about the table
A sql database can have many tables, so its useful to take a look at whats there:
%sqlcmd tables| Name |
|---|
| bigmac |
This should describe the table:
%sql describe bigmac;| Success |
|---|
The describe bigmac code should spit out table info, seems to be some kind of bug, but moving on, we can get the gist using the information schema:
%%sql
SELECT COLUMN_NAME, DATA_TYPE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = 'bigmac';| column_name | data_type | |
|---|---|---|
| 0 | name | VARCHAR |
| 1 | iso_a3 | VARCHAR |
| 2 | currency_code | VARCHAR |
| 3 | local_price | DOUBLE |
| 4 | dollar_ex | DOUBLE |
| 5 | GDP_dollar | DOUBLE |
| 6 | GDP_local | DOUBLE |
| 7 | date | DATE |
The above is not that useful, a more informative look which counts the values is:
%sqlcmd profile --table 'bigmac'| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1918 | 1918 | 1918 | 1918 | 1918 | 1918 | 1918 | 1918 | 1918 | 1918 | 1918 |
| unique | 73 | 72 | 56 | 655 | 1473 | 1141 | 1141 | 37 | 1827 | 1835 | 1790 |
| top | Argentina | ARG | EUR | nan | nan | nan | nan | 2018-07-01 | nan | nan | nan |
| freq | 37 | 37 | 350 | nan | nan | nan | nan | 72 | nan | nan | nan |
| mean | nan | nan | nan | 7559.2864 | 2870.1936 | 25020.0618 | 2615423.9573 | nan | 3.4740 | -0.1340 | 26351.7044 |
| std | nan | nan | nan | 154285.8636 | 58921.0338 | 21466.5984 | 9471890.5225 | nan | 1.2289 | 0.3013 | 19541.3083 |
| min | nan | nan | nan | 1.05 | 0.3008 | 689.826 | 3004.341 | nan | 0.64 | -0.7409 | 0.0022 |
| 25% | nan | nan | nan | 4.4200 | 1.0000 | 6598.8800 | 33698.7640 | nan | 2.5118 | -0.3530 | 8516.5585 |
| 50% | nan | nan | nan | 14.7500 | 5.3375 | 18167.3440 | 70506.5530 | nan | 3.4129 | -0.1755 | 23327.7564 |
| 75% | nan | nan | nan | 85.0000 | 32.1055 | 41469.7730 | 358689.5130 | nan | 4.3132 | 0.0220 | 40981.9351 |
| max | nan | nan | nan | 4000000.0 | 1600500.0 | 102576.68 | 85420189.717 | nan | 8.3117 | 1.5347 | 98893.859 |
Data cleanup
So we have 3 rows without a GDP_dollar, and at least one local_price and dollar_ex of 0, so dropping those rows. We also need GDP_local to be able to adjust the bigmac index, so dropping any nulls in that row too.
%%sql
delete from bigmac where
GDP_dollar is null or GDP_local is null or local_price<=0 or dollar_ex<=0;| Success |
|---|
rows = %sql select count(*) as N from bigmac;
f"The data set has a total of {rows.N.loc[0]} rows."'The data set has a total of 1918 rows.'It’s a pretty clean and tidy dataset, we did loose a few rows, which in a real world case might bear more investigation, but moving on…
%sql select count(distinct name) as Countries, min(date), max(date) from bigmac;| Countries | min(date) | max(date) | |
|---|---|---|---|
| 0 | 73 | 2000-04-01 | 2022-07-01 |
We have data for 73 countries from April 2000 to July 2022.
Calculations in SQL
Adding some columns by calculating new ones in sql. This is where the sql starts.
Big mac price in USD
We want to get the US dollar price for a big mac in every country, which is easy as our data contains the local_price and dollar exchange rate. So we add a new column: dollar_price = local_price / dollar_ex.
In sql you can’t just add a column, you first have to add it with a value type. In pandas you can do this in one step: df["dollar_price"] = df.local_price / df.dollar_ex.
So here we add a new col dollar_price and calc its value:
%%sql
alter table bigmac
add column if not exists dollar_price DOUBLE;
update bigmac
set dollar_price = local_price / dollar_ex;
select * from bigmac limit 3;| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | ARS | 2.50 | 1.00 | 8709.072 | 8709.072 | 2000-04-01 | 2.500000 | 0.116071 | 7803.328512 |
| 1 | Australia | AUS | AUD | 2.59 | 1.68 | 21746.809 | 33698.764 | 2000-04-01 | 1.541667 | -0.311756 | 29144.876973 |
| 2 | Brazil | BRA | BRL | 2.95 | 1.79 | 3501.438 | 6351.375 | 2000-04-01 | 1.648045 | -0.264266 | 4822.738983 |
The line if not exists is optional, but useful in this context as it prevents errors if I rerun the notebook.
Calculating the big mac index
Now we want to account for purchasing power parity by divinding the dollar price with the base currencies price. The Economist uses five base currencies: ('USD', 'EUR', 'GBP', 'JPY', 'CNY')
For simplicity’s sake, I’ll stick with just USD. This is a easy calc to do in python, in SQL its a bit messy…, so I am using Correlated Subqueries in SQL to do this.
The dollar_price on each row is divided by the dollar_price in USD. Since we have multiple dates, the query below matches on both the date and the country code.
The inner query returns the US dollar_price for each date, so every row in the table gets divided by the right dates USD price.
Note
This only works because for each unique date, there is only one row for USA.
Finally, we minus the number by -1, as we divide the US price by its own, so its always at 1. By subtracting -1, we set that to zero, which makes it wasy to see how the other countries are over or under that.
%%sql
ALTER TABLE bigmac ADD COLUMN IF NOT EXISTS USD DOUBLE;
update bigmac as b1
set USD = dollar_price /
(select b2.dollar_price from bigmac as b2
where b2.date = b1.date
and b2.iso_a3 = 'USA') - 1;
select * from bigmac order by date desc, name desc limit 6;| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Vietnam | VNM | VND | 69000.00 | 23417.00000 | 3724.543 | 8.542019e+07 | 2022-07-01 | 2.946577 | -0.427849 | 6375.564885 |
| 1 | Uruguay | URY | UYU | 255.00 | 41.91000 | 16756.344 | 7.291942e+05 | 2022-07-01 | 6.084467 | 0.181450 | 14726.863618 |
| 2 | United States | USA | USD | 5.15 | 1.00000 | 69231.400 | 6.923140e+04 | 2022-07-01 | 5.150000 | 0.000000 | 69231.400000 |
| 3 | United Arab Emirates | ARE | AED | 18.00 | 3.67305 | 42883.686 | 1.574903e+05 | 2022-07-01 | 4.900559 | -0.048435 | 45059.735594 |
| 4 | Turkey | TUR | TRY | 47.00 | 17.56500 | 9527.683 | 8.448134e+04 | 2022-07-01 | 2.675776 | -0.480432 | 9256.997784 |
| 5 | Thailand | THA | THB | 128.00 | 36.61250 | 7336.086 | 2.313028e+05 | 2022-07-01 | 3.496074 | -0.321151 | 9306.323554 |
I did a few random checks and looks like the formula did use the right USD price to calculate the USD offset.
Adjusted GDP based on big mac index
Big Mac adjusted per capita GDP is the GDP in local currency divided by the exchange rate as determined by big macs (price in local currency divivded by price in US).
The formula is: GDP_Local / (local_price / dollar_price)
%%sql
ALTER TABLE bigmac ADD COLUMN IF NOT EXISTS GDP_bigmac DOUBLE;
update bigmac as b1
set GDP_bigmac = GDP_local /
(local_price / (select b2.dollar_price from bigmac as b2
where b2.date = b1.date
and b2.iso_a3 = 'USA'));
select * from bigmac order by date desc, name desc limit 6;| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Vietnam | VNM | VND | 69000.00 | 23417.00000 | 3724.543 | 8.542019e+07 | 2022-07-01 | 2.946577 | -0.427849 | 6375.564885 |
| 1 | Uruguay | URY | UYU | 255.00 | 41.91000 | 16756.344 | 7.291942e+05 | 2022-07-01 | 6.084467 | 0.181450 | 14726.863618 |
| 2 | United States | USA | USD | 5.15 | 1.00000 | 69231.400 | 6.923140e+04 | 2022-07-01 | 5.150000 | 0.000000 | 69231.400000 |
| 3 | United Arab Emirates | ARE | AED | 18.00 | 3.67305 | 42883.686 | 1.574903e+05 | 2022-07-01 | 4.900559 | -0.048435 | 45059.735594 |
| 4 | Turkey | TUR | TRY | 47.00 | 17.56500 | 9527.683 | 8.448134e+04 | 2022-07-01 | 2.675776 | -0.480432 | 9256.997784 |
| 5 | Thailand | THA | THB | 128.00 | 36.61250 | 7336.086 | 2.313028e+05 | 2022-07-01 | 3.496074 | -0.321151 | 9306.323554 |
And presto, we have a gdp per big mac, which for most countries is significantly different from each other. A couple of plots to eyeball this:
Code
df = %sql select * from bigmac;
fig, ax = plt.subplots(figsize=(8, 4))
ax.spines[["top", "right"]].set_visible(False)
ax.set_title("GDP Bigmac vs dollar", loc="left", weight="bold")
for name in ["Pakistan", "India"]:
d = df.query("name == @name")
ax.plot(d.date, d.GDP_bigmac, alpha=0.8, label=f"{name}")
ax.fill_between(d.date, d.GDP_bigmac, d.GDP_dollar, alpha=0.12)
#ax.plot(d.date, d.GDP_dollar, alpha=0.6, ls="--")
ax.legend();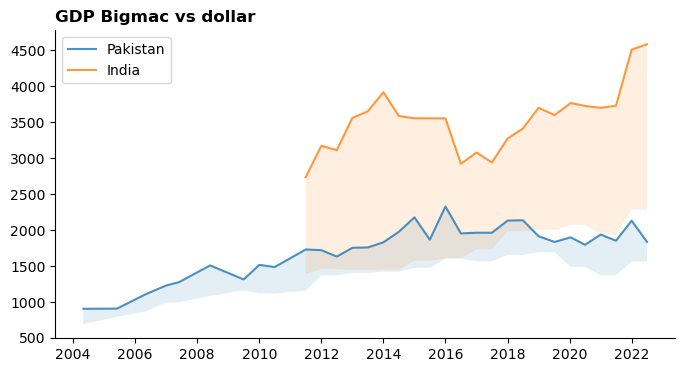
Code
country = "Pakistan"
df = %sql select * from bigmac where name in ('{{country}}')
fig = px.line(df, x="date", y=["GDP_dollar", "GDP_bigmac"],
title=f"{country}: GDP local vs bigmac",
markers=True)
fig.show()This is interesting, you can see the indian dollar even though its close to the Pakistan one in GDP_dollar terms, the big mac index GDP says it buys a lot more.
TODO: Adjusted big mac index
This uses the big mac adjusted per capita GDP price calculated above to get a adjusted dollar price for a bigmac. This looks very similar to first big mac index so left this calc for a future date.
See Calculating the adjusted index for details.
Moar data - adding in country data
There are a lot of countries in the index, which will make the graph a bit messy, so to add some groups to the counties (and do more sql!) I’m going to use the world banks income dataset, primary to add regions and income groups.
df_income = pd.read_excel(
"https://datacatalogfiles.worldbank.org/ddh-published/0037712/DR0090755/CLASS.xlsx"
)
df_income = (
df_income.dropna(subset=["Income group", "Economy"])
.drop(columns="Lending category")
.rename(columns={"Code": "iso_a3", "Income group": "income_group"})
)
# adding in the missing eurozone
euro_row = ["Eurozone", "EUZ", "Europe", "High income"]
df_income.loc[len(df_income)] = euro_row
df_income.tail(3)| Economy | iso_a3 | Region | income_group | |
|---|---|---|---|---|
| 215 | South Africa | ZAF | Sub-Saharan Africa | Upper middle income |
| 216 | Zambia | ZMB | Sub-Saharan Africa | Lower middle income |
| 217 | Eurozone | EUZ | Europe | High income |
No need to do this step, but for more sql goodness, lets add this as a table in our database so we can practice joining two tables:
%%sql
create table income as select * from df_income;
select * from income limit 3;RuntimeError: (duckdb.CatalogException) Catalog Error: Table with name "income" already exists!
[SQL: create table income as select * from df_income;]
(Background on this error at: https://sqlalche.me/e/20/f405)
If you need help solving this issue, send us a message: https://ploomber.io/communityJoining the two tables
Here we join these two tables into a dataframe for plotting.
I am using a left join as I want to keep all data in the bigmac table, and just add country info.
Warning
Don’t write sql like below, use capitals and linebreaks!
df_all = %sql select * from bigmac left join income on bigmac.iso_a3 = income.iso_a3 order by bigmac.date asc;
df_all.head(2)| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | Economy | iso_a3_2 | Region | income_group | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | ARS | 2.50 | 1.00 | 8709.072 | 8709.072 | 2000-04-01 | 2.500000 | 0.116071 | 7803.328512 | Argentina | ARG | Latin America & Caribbean | Upper middle income |
| 1 | Australia | AUS | AUD | 2.59 | 1.68 | 21746.809 | 33698.764 | 2000-04-01 | 1.541667 | -0.311756 | 29144.876973 | Australia | AUS | East Asia & Pacific | High income |
Everything looks good here, we now have a dataframe which combines the two tables and is ready to plot.
Save data to disk
For using in a future something.
df_all.to_parquet("bigmac_index_data_ko.parquet")Big Mac Index chart using Matplotlib
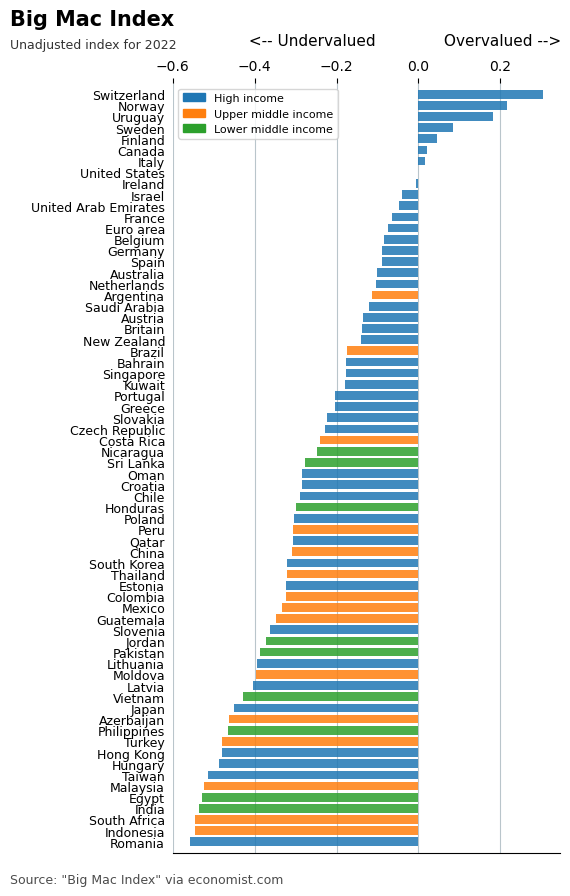
This is going to be ugly, but its good matplotlib practice. First up, for the economist plot we just want the latest date:
df = df_all.query("date == date.max()").sort_values("USD")
df.head(2)| name | iso_a3 | currency_code | local_price | dollar_ex | GDP_dollar | GDP_local | date | dollar_price | USD | GDP_bigmac | Economy | iso_a3_2 | Region | income_group | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1899 | Romania | ROU | RON | 11.0 | 4.82175 | 14667.089 | 6.102120e+04 | 2022-07-01 | 2.281329 | -0.557023 | 28569.017768 | Romania | ROU | Europe & Central Asia | High income |
| 1876 | Indonesia | IDN | IDR | 35000.0 | 14977.50000 | 4356.560 | 6.233566e+07 | 2022-07-01 | 2.336839 | -0.546245 | 9172.246719 | Indonesia | IDN | East Asia & Pacific | Upper middle income |
Code
fig, ax = plt.subplots(figsize=(5, 10))
ax.spines[["top", "right", "left"]].set_visible(False)
ax.set_title(
"Big Mac Index", loc="left", weight="bold", ha="left", fontsize=15, x=-0.42
)
ax.text(
x=-0.2,
y=0.915,
s="Unadjusted index for 2022",
transform=fig.transFigure,
ha="left",
fontsize=9,
alpha=0.8,
)
# plotting the actual data
# assigning each income group a color
color_list = list(mcolors.TABLEAU_COLORS.values())
colors = {country: color_list[i] for i, country in enumerate(df.income_group.unique())}
# the actual plot
ax.barh(
y=df.name,
width=df.USD,
alpha=0.85,
height=0.78,
color=[colors[income] for income in df.income_group],
zorder=2,
)
# x axis things
ax.xaxis.tick_top()
ax.set_xlabel(
" <-- Undervalued Overvalued --> ",
labelpad=10,
fontsize=11,
)
ax.xaxis.set_label_position("top")
# fix and label the y axis
# ax.set_yticklabels(df.name, ha="left")
ax.yaxis.set_tick_params(pad=2, labelsize=9, bottom=False)
ax.set_ylim(-1, df.shape[0])
# legend for income groups
handles = [mpatches.Patch(color=colors[i]) for i in colors]
labels = [f"{i}" for i in colors]
ax.legend(handles, labels, fontsize=8)
ax.grid(which="major", axis="x", color="#758D99", alpha=0.5, zorder=1)
# Set source text
ax.text(
x=-0.2,
y=0.08,
s="""Source: "Big Mac Index" via economist.com""",
transform=fig.transFigure,
ha="left",
fontsize=9,
alpha=0.7,
);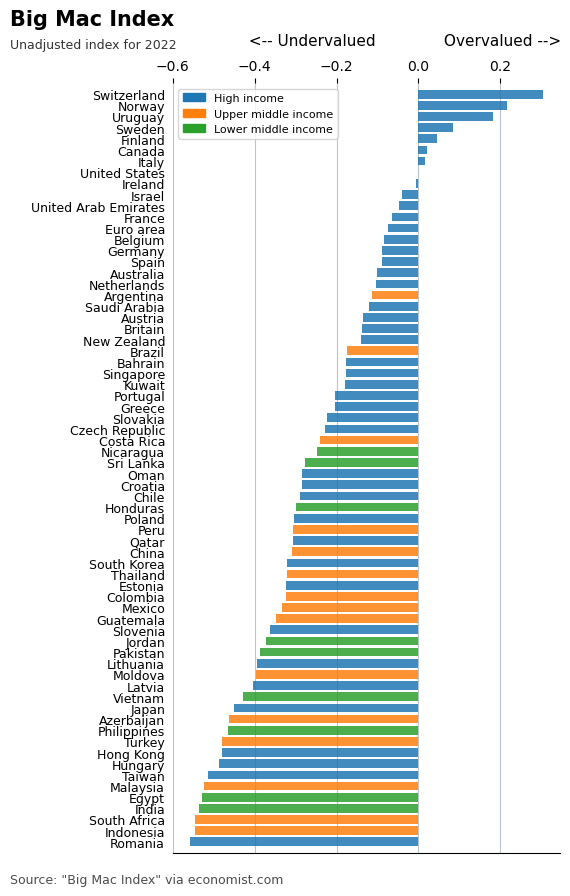
phew! That is a long image, with too many countries, and its a bit ugly, so if this was going to be used somewhere, I’d filter the countries and produce a more sensible sized graph.
Big Mac Index using Plotly
I should have probably gone with plotly first for this, but here goes:
fig = px.bar(
df, x="USD", y="name", width=600, height=800, text="name", color="income_group"
)
fig.update_layout(title_text="Big Mac Index", yaxis_categoryorder="total ascending")
fig.show()Big mac index with trendlines
This is a bit messy again… but here goes some plotly practice:
Code
names = df_all.name.unique()
show_countries = ["Pakistan", "India"]
fig = px.scatter(df_all, x="date", y="USD", color="name", opacity=0.8,
trendline="lowess")
# add a text label to the end of each scatter plot
max_date = df_all.date.max()
df = df_all.query("date == @max_date")
for name in df.name:
fig.add_trace(go.Scatter(opacity=0.6,
x=df.query("name == @name").date,
y=df.query("name == @name").USD + 0.15,
mode="text",
legendgroup=name,showlegend=False,
name=name,
text=name,
textposition="top center",
))
# turn off plots
fig.for_each_trace(lambda trace: trace.update(visible='legendonly')
if trace.name not in show_countries else ())
#fig.for_each_trace(lambda trace: trace.update(opacity=0.09)
# if trace.name not in show_countries else ())
fig.add_hline(y=0, opacity=0.5, visible=True, line_width=1)
fig.update_layout(title="Big Mac Index with country selector", template="simple_white")
fig.update_yaxes(tickformat=".0%", dtick=0.2, range=[-0.7, 0.7],
showspikes=True, spikethickness=0.5)
fig.update_xaxes(showspikes=True, spikethickness=0.5)
fig.add_trace(go.Scatter(
x=[2022],
y=[0.01],
mode="text",
name="US dollar",
text=["US dollar"],
textposition="top center"
))
fig.show()Code
names = df_all.name.unique()
show_countries = ["Pakistan"]
colors = ["red" if usd < 0 else "#1f77b4" for usd in df_all.USD]
fig = px.scatter(df_all, x="date", y="USD", opacity=0.05).update_traces(
marker=dict(color=colors))
# add a text label to the end of each scatter plot
max_date = df_all.date.max()
df = df_all.query("date == @max_date")
for name in show_countries:
dff = df.query("name == @name")
fig.add_traces(
px.line(df_all.query("name==@name"),
x="date", y="USD").data[:]
)
fig.add_trace(go.Scatter(opacity=0.6,
x=dff.date,
y=dff.USD + 0.15,
mode="text",
legendgroup=name,showlegend=False,
name=name,
text=name,
textposition="top center",
))
# turn off plots
#fig.for_each_trace(lambda trace: trace.update(visible='legendonly')
# if trace.name not in show_countries else ())
#fig.for_each_trace(lambda trace: trace.update(opacity=0.09)
# if trace.name not in show_countries else ())
fig.add_hline(y=0, opacity=0.5, visible=True, line_width=0.8)
fig.update_layout(title="Big Mac Index highlighting a country", template="simple_white")
fig.update_yaxes(tickformat=".0%", dtick=0.2, range=[-0.7, 0.7],
showspikes=True, spikethickness=0.5)
fig.update_xaxes(showspikes=True, spikethickness=0.5)
fig.add_trace(go.Scatter(
x=[2022],
y=[0.01],
mode="text",
name="US dollar",
text=["US dollar"],
textposition="top center"
))
fig.show()The above graph has some issues, to be fixed later. Looks like this would be simpler in Altair instead of plotly.
from plotly.subplots import make_subplots
fig = make_subplots(rows=1, cols=2)
fig = px.choropleth(df, color="USD", locations="iso_a3",
title="Big Mac Index", hover_name="name")
fig.update_layout(height=600, width=800)
fig.show()Altair
Altair seems useful for this too… trying it out
Code
import altair as alt
highlight = alt.selection_point(on='mouseover', fields=['name'], nearest=True)
base = alt.Chart(df_all).encode(
x='date:T',
y='USD:Q',
color='name:N',
tooltip=['name', 'date','USD']
)
points = base.mark_circle().encode(
opacity=alt.value(0.01)
).add_params(
highlight
).properties(
width=600
)
lines = base.mark_line().encode(
size=alt.condition(~highlight, alt.value(0.2), alt.value(3))
)
points + linesname = "Pakistan"
df = df_all.query("name == @name")
chart = alt.Chart(df).mark_area(
opacity=0.7, color="red", line=True).encode(
x="date:T",
y=alt.Y("USD:Q")
)
chartthe end
Can play around a bit more with this data… but heaps enough for now. The economist has a great dashboard to this very simple dataset, so a good future dashboarding exercise is to make something which lookls like that.